

How an Optical Character Recognition (OCR) Works?
Have you ever had to scan a document and needed the text to be editable? This is where optical character recognition (OCR) comes in handy. OCR is the process of translating/extracting text(characters) from a scanned file/image. By doing so, we can even recognize text and extract printed, typed, or handwritten content from physical files into edible digital documents. Let’s take a closer look at OCR.
OCR, or optical character recognition, is the process of recognizing text withier it is printed or handwritten from scanned files (images/Pdfs). OCR platforms such as AlgoDocs use AI and Image Processing to extract and translate content into useful, accurate text.
This article has two goals, we’ll discuss the technical information about OCR and review AlgoDocs, which is a powerful web-based AI platform for data extraction. Its developed algorithms rely on image processing and Optical Character Recognition (OCR) technologies with a human vision attitude. Therefore, AlgoDocs has reliable and accurate data extraction with high accuracy results.
AlgoDocs offers a free forever subscription that we can use to extract data such as tables and handwritten from 50 pages per month. Also, you can check AlgoDocs affordable pricing plans if you need to process a higher number of pages.
How OCR Works?
First, OCR works on detecting and defining different elements present in the image. OCR is capable of deciphering both directions of characters as well as readability. One benefit of OCR is the git ride of human errors while manually extracting the information or when the document has already some incorrect data, such as:1) Numeric content output with special glyphs, 2) Line alignment issues, and 3) Overlapped fonts, which often occur due to fonts’ imaging features.
OCR isn’t 100% perfect, and its output may have errors. For instance, the type of character contained in the image is based on font, the angle from which the image is scanned, and the properties, fonts, and graphics within the image, whereas sometimes, in poor quality scanned files, some characters can be wrongly interpreted like “m” can be interpreted as “n” and vice versa.
Why is OCR important?
In our digital world, data is everything. The more data we have, the more insights we can glean, and the better decisions we can make. That’s why optical character recognition (OCR) is so essential – it extracts data from scanned documents, images, and PDFs, making it available for further analysis. Think about all the data out there just waiting to be pulled. Financial reports, medical records, legal documents, academic papers – the list goes on and on. With OCR, that data can be transformed from a jumble of characters into a usable format that provides valuable insights. And OCR isn’t just for businesses – it’s also used extensively almost everywhere, for instance, schools and universities are using it to digitize textbooks and other course materials.
Back to AlgoDocs, in summary, its main Features are:
1) Extract Tables from PDF and Scanned Documents
Have you ever had a situation where you needed to copy a table from a book or a scanned file? It is a complicated and tedious process in most cases. Since copying and pasting tables from such a file even if it was computer-generated to a word Excel spreadsheet is a challenging task. AlgoDocs allows us to easily extract tables, even the most complex tables and the ones allocated on multiple pages using a user-friendly interface.
The following are the steps to follow when extracting tables from documents using AlgoDocs:
- Create an extractor by uploading a sample document
- In extracting rules editor, add a rule by selecting the ‘Table’ as the data type.
- Place column separators on the table
- Click on the ‘Extract’ button to extract the table and apply various filters to refine and convert the extracted table into the format you need.
- Finally, export extracted tables to an editable file such as Excel or JSON.
You can check the free Video Tutorials, which demonstrate how to extract tables from pdf or scanned documents.
2) Extracting Tables from Low-Quality Scanned Documents
AlgoDocs has an advanced AI-powered OCR engine that can handle even low-quality scanned pdf and images. AlgoDocs processes colorful and black and white scanned images, and it can process scanned images with as low dpi as 75.
Consider the portions of the scanned documents below (Figure1), while Figure2 shows the tables extracted by AlgoDocs.

Figure1. Low quality scanned image (black & white) uploaded to AlgoDocs.
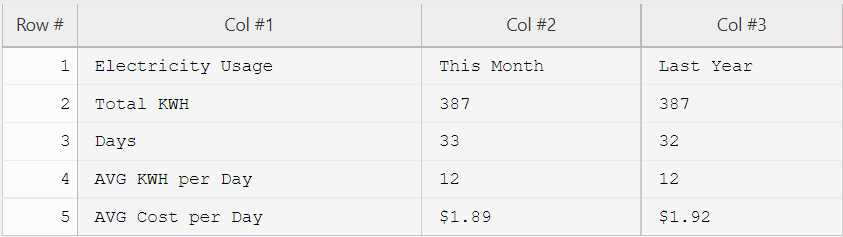
Figure2. The extracted table from the image shown in Figure1 using AlgoDocs.
3) Extract Handwritten Text from Scanned PDF and Images
AlgoDocs has an ICR (Intelligent Character Recognition) function that can convert handwritten text into machine-printed text. Hence, it removes drudgery and manual data entry errors and can also benefit your existing workflow.
Let’s consider the following sheet of a handwritten scanned document(Figure3), which contains numbers in Table format.

Figure 3. Sample of a scanned handwritten text.
If you upload the above image (Figure 3) to your account at AlgoDocs, you will see a 100% accurate output presented in Figure 4.
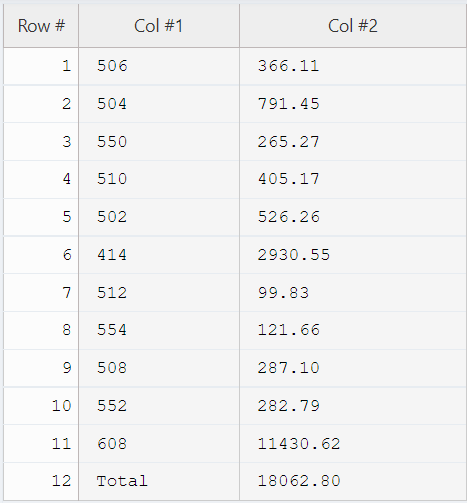
Figure4. The extracted table, using AlgoDocs, from the scanned image shown in Figure3.
4) Convert PDF Documents to Structured JSON Objects( PDF to JSON)
AlgoDocs can extract multiple fields and tables from native and scanned PDF documents in real time and in only three steps.
The following steps show how you can conveniently extract data from scanned documents into JSON files.
- First, start by creating an extractor in AlgoDocs. AlgoDocs has some preprocessing operations that take some time depending on the number of pages your PDF document contains; usually, it is around 15-20 seconds.
- Then, go to the ‘Extracting Rules’ editor to create your extracting rules for every field you need to extract from your PDF documents. Similarly, if you need to extract tables from your PDF documents, you can create extracting rules for tables by selecting ‘Table’ as the data type.
- After creating rules, you can upload hundreds of thousands of PDF documents using the file manager in AlgoDocs or import your documents via Google Drive, Dropbox, Zapier, AlgoDocs Inbound Email, or AlgoDocs API.
Remember that you will create an extractor only once, then, import documents as much as you need.
- Finally, export extracted data to multiple formats like JSON, Excel or XML, or even send it to hundreds of different applications in real-time.
You can check the free Video Tutorial, which demonstrates how you can Convert PDF to JSON.


